
Google Search Console has suspended the URL Inspection tool for a week and till then automatic crawling and indexing will be working as normal but the manual inspection will be suspended for the week.
As it was measured from the previous 3 weeks the indexing problem on google Search so to make the vital changes in search console google has restricted users to use that tool and the rest of the other features will be continued as normal always.
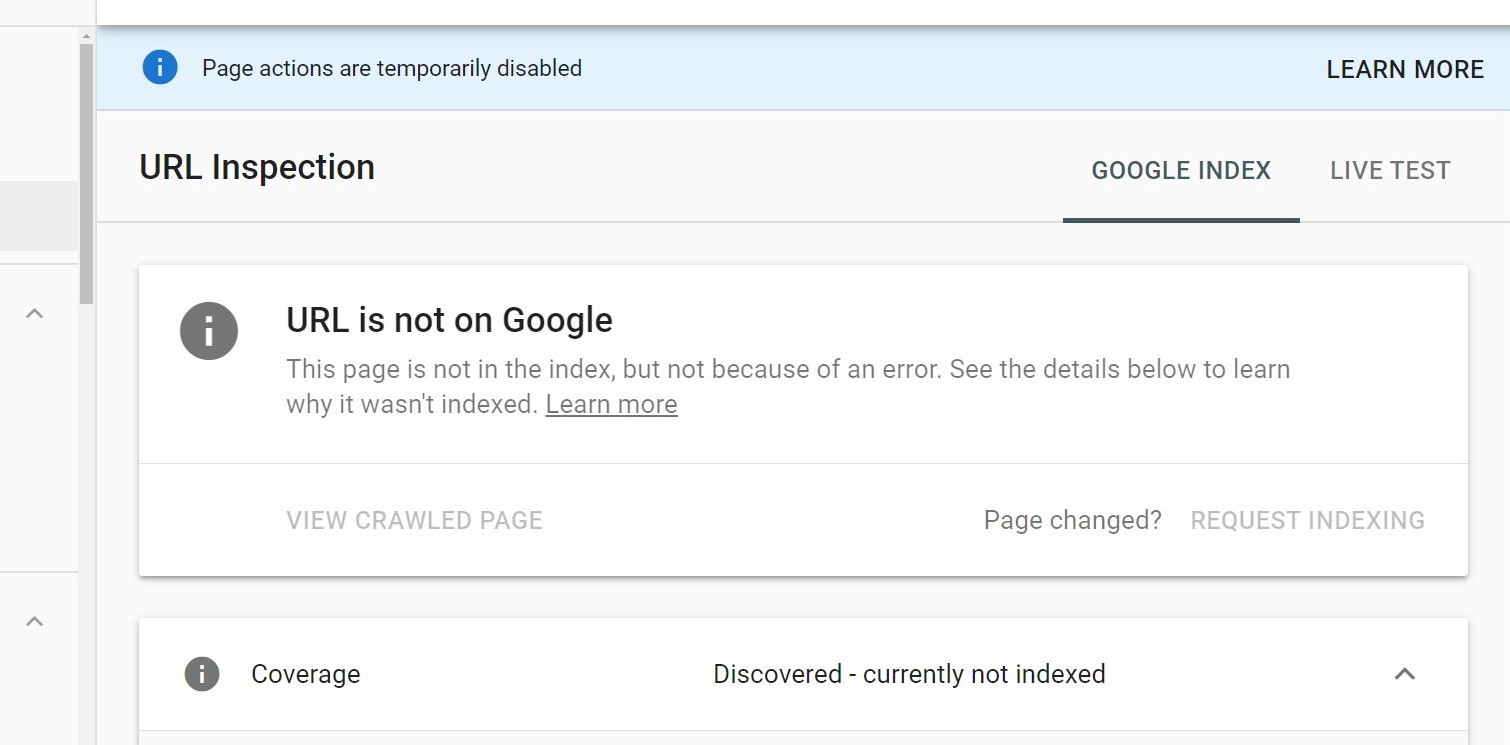
Statement from Google:
URL Inspection tool
2020
October 14, ongoing
The “Request Indexing” feature of the URL Inspection Tool has been disabled in order to make some technical updates. We expect it to be re-enabled in the coming weeks. In the meanwhile, Google continues to find and index content through our regular methods, as covered here.
Below content is taken from google just to Aware Readers:
How Google Search Works
Learn how Google discovers, crawls, and serves web pages
How does Google work? Here is a short version and a long version.
Google gets information from many different sources, including:
- Web pages,
- User-submitted content such as Google My Business and Maps user submissions,
- Book scanning,
- Public databases on the Internet,
- and many other sources.
- However, this page focuses on web pages.
The short version
Google follows three basic steps to generate results from web pages:
Crawling
The first step is finding out what pages exist on the web. There isn’t a central registry of all web pages, so Google must constantly search for new pages and add them to its list of known pages. Some pages are known because Google has already visited them before. Other pages are discovered when Google follows a link from a known page to a new page. Still other pages are discovered when a website owner submits a list of pages (a sitemap) for Google to crawl. If you’re using a managed web host, such as Wix or Blogger, they might tell Google to crawl any updated or new pages that you make.
Once Google discovers a page URL, it visits, or crawls, the page to find out what’s on it. Google renders the page and analyzes both the text and non-text content and overall visual layout to decide where it should appear in Search results. The better that Google can understand your site, the better we can match it to people who are looking for your content.
To improve your site crawling:
Verify that Google can reach the pages on your site, and that they look correct. Google accesses the web as an anonymous user (a user with no passwords or information). Google should also be able to see all the images and other elements of the page to be able to understand it correctly. You can do a quick check by typing your page URL in the Mobile-Friendly test tool.
If you’ve created or updated a single page, you can submit an individual URL to Google. To tell Google about many new or updated pages at once, use a sitemap.
If you ask Google to crawl only one page, make it your home page. Your home page is the most important page on your site, as far as Google is concerned. To encourage a complete site crawl, be sure that your home page (and all pages) contain a good site navigation system that links to all the important sections and pages on your site; this helps users (and Google) find their way around your site. For smaller sites (less than 1,000 pages), making Google aware of only your homepage is all you need, provided that Google can reach all your other pages by following a path of links that start from your homepage.
Get your page linked to by another page that Google already knows about. However, be warned that links in advertisements, links that you pay for in other sites, links in comments, or other links that don’t follow the Google Webmaster Guidelines won’t be followed by Google.
Google doesn’t accept payment to crawl a site more frequently, or rank it higher. If anyone tells you otherwise, they’re wrong.
Indexing
After a page is discovered, Google tries to understand what the page is about. This process is called indexing. Google analyzes the content of the page, catalogs images and video files embedded on the page, and otherwise tries to understand the page. This information is stored in the Google index, a huge database stored in many, many (many!) computers.
To improve your page indexing:
Create short, meaningful page titles.
Use page headings that convey the subject of the page.
Use text rather than images to convey content. (Google can understand some image and video, but not as well as it can understand text. At minimum, annotate your video and images with alt text and other attributes as appropriate.)
Serving (and ranking)
When a user types a query, Google tries to find the most relevant answer from its index based on many factors. Google tries to determine the highest quality answers, and factor in other considerations that will provide the best user experience and most appropriate answer, by considering things such as the user’s location, language, and device (desktop or phone). For example, searching for “bicycle repair shops” would show different answers to a user in Paris than it would to a user in Hong Kong. Google doesn’t accept payment to rank pages higher, and ranking is done programmatically.
To improve your serving and ranking:
Make your page fast to load, and mobile-friendly.
Put useful content on your page and keep it up to date.
Follow the Google Webmaster Guidelines, which help ensure a good user experience.
Read more tips and best practices in our SEO starter guide.
You can find more information here, including the guidelines that we provide to our quality raters to ensure that we’re providing good results
The long version
Want more information? Here it is: